I've been thinking about what changes when you talk to an agent instead of typing at it. Not the technology. The relationship.
Text is asynchronous. That word does most of the work.
When I type a prompt into a model, I'm writing a letter. I might take two seconds over the sentence. I might take five minutes. I might start, walk away, make a coffee, come back, change my mind, delete it, start again. The model doesn't know. The model doesn't care. It receives a finished artefact and replies to that artefact.
The same is true going the other way. The model can take ten seconds to answer. It can take three minutes. If it needs to go look something up, spin up a tool, think harder — fine. I'll be here. The clock doesn't run between us. The conversation happens in two separate timezones that occasionally exchange post.
This is an enormous, underrated affordance. Async means the model can be slow when it needs to be slow. Async means I can be slow when I need to be slow. Neither of us has to perform fluency. The conversation can carry weight that real-time conversations can't.
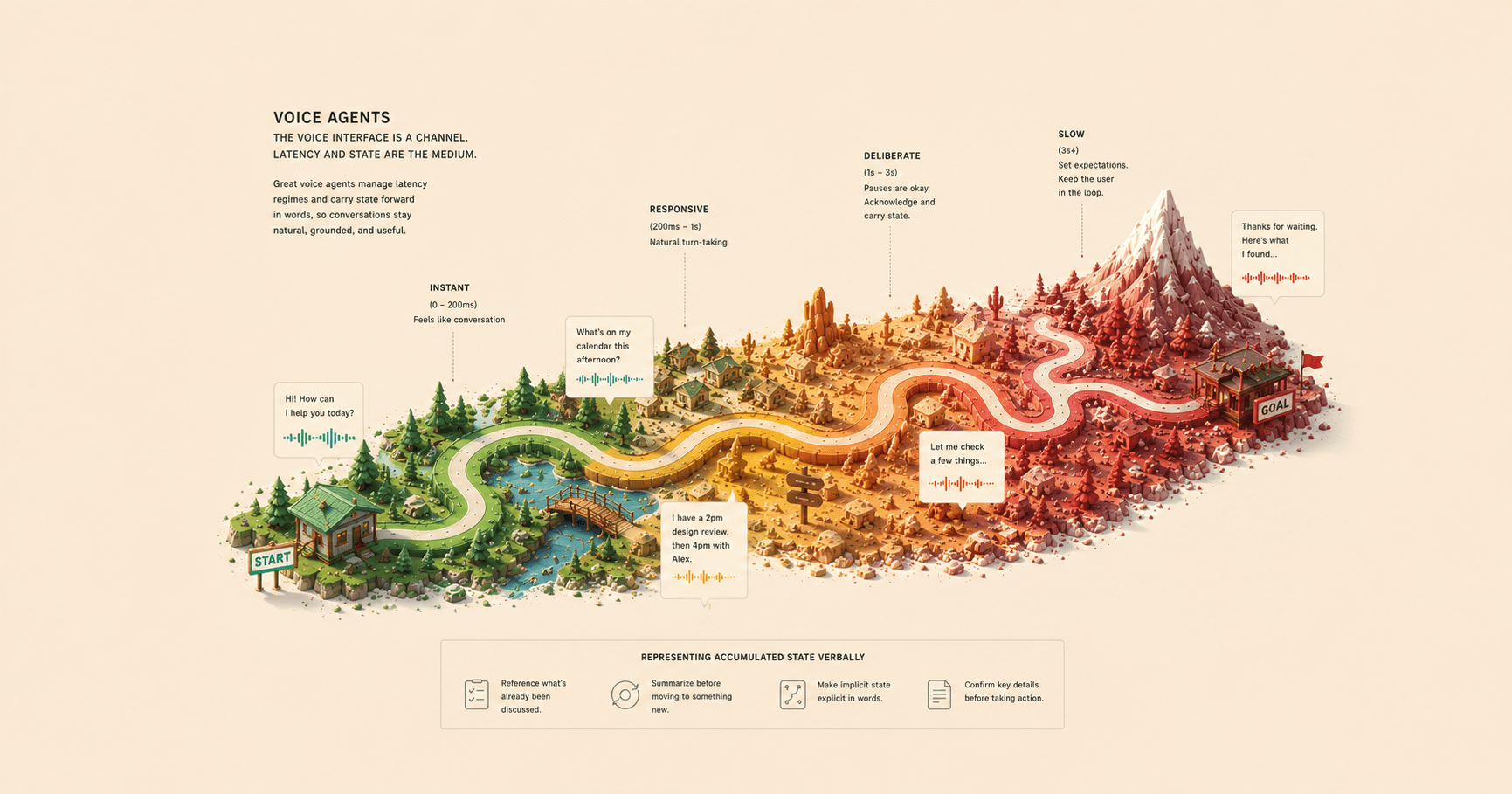
Voice is synchronous. That word also does most of the work.
When I talk to an agent, the clock is running. Every second of silence is content. If I pause to think, the agent has to decide whether I'm done or just gathering myself. If the agent pauses to think, I have to decide whether it's working or whether the line dropped. Silence in a voice channel reads as malfunction. You can't take three minutes to formulate a reply. You can't take thirty seconds.
This changes what the agent is allowed to do.
An async agent can do real work in-line. Go read the doc. Run the query. Try three approaches. Come back with a real answer. The user has gone to lunch; their answer is ready when they get back.
A synchronous agent cannot do any of that. It has, roughly, the length of a polite pause. After that, it has to be saying something, or the conversation collapses. So the work has to happen somewhere else.
Voice agents have to hand off.
Not in the sense of "transfer me to a human". In the sense that the real work — the slow work, the careful work, the work that earns its answer — cannot happen inside the voice turn. The voice agent's job is to take the brief and promise the work. The work itself goes somewhere with a different clock.
The shape of a good voice interaction starts to look less like "ask the agent a question, get an answer" and more like "tell the agent what you need, then go and find it done." Voice is the intake. Async is the delivery. They are not the same conversation, and they shouldn't pretend to be.
A text agent is allowed to be a craftsman. It can disappear for a minute and come back with something good.
A voice agent has to be a receptionist. Warm, attentive, fast, and very clear that the actual work is happening down the hall.
The other thing voice changes — and I'll be brief about this because it's obvious once you notice it — is the quality of presence.
Text agents live in a tab. You open the tab when you want them. You close the tab when you're done. They have no claim on your attention.
Voice agents are in the room. You can hear them. They can hear you. If they speak, you have to acknowledge them, even if only to say "hold on". They have, by default, a kind of social weight that a text agent has to work hard to earn.
This is good and bad. Good because it makes the agent feel like a participant rather than a tool. Bad because not every interaction should feel like a participant. Sometimes you want the tool. Sometimes you want to type at the cursor for forty minutes and not be spoken to.
The mistake a lot of products are about to make, I think, is treating voice as an upgrade — as "text, but better, but more present." It isn't. It's a different mode with a different etiquette and a much shorter latency budget. Adding voice to a thing doesn't make the thing more capable. It makes the thing more immediate, which is sometimes what you want and sometimes the last thing you want.
The way to think about it, is that text and voice are not two interfaces to the same agent. They're two different relationships with the same colleague.
One you brief by email. They take their time. They come back with the goods.
The other you grab in the corridor. They can't go and do the work in front of you. But they can hear what you actually meant, faster than you could ever have written it down.
The trick, for anyone building this stuff, is knowing which one the user came for.
We introduced Realtime voice in Sauna, you can start using it today at app.sauna.ai. Or just have a quick play at voicetest.sauna.show