
Choosing the right large language model isn’t just about leaderboard scores anymore. The best way to figure out which model fits your needs is to try them side by side and pay attention to how they feel in real use.
Accuracy matters. But so does tone, clarity, and how much you actually enjoy using the model.
The Current LLM Leaders (For Now)
Each top model brings something different to the table:
GPT (OpenAI) Great at reasoning, creativity, and code. Known for emotional tone and clear summaries.
Claude (Anthropic) Strong on safety, long context, and nuanced answers. Often the go-to for business use.
Gemini (Google) Best at search-like tasks and multimodal inputs. Analytical and structured.
Llama (Meta) Open-source, fast, and surprisingly funny. Easy to customize.
Qwen (Alibaba) Strong at math, logic, and clean outputs. Direct and no-frills.
Grok (xAI) Pulls real-time data and trends. Witty, casual tone.
DeepSeek Ranks well across many benchmarks. Consistent, thoughtful responses.
That said, the leaderboard changes every week as model upgrades role out.
How Do You Find the Best Model to Use?
Strategy #1: Use Community Leaderboards
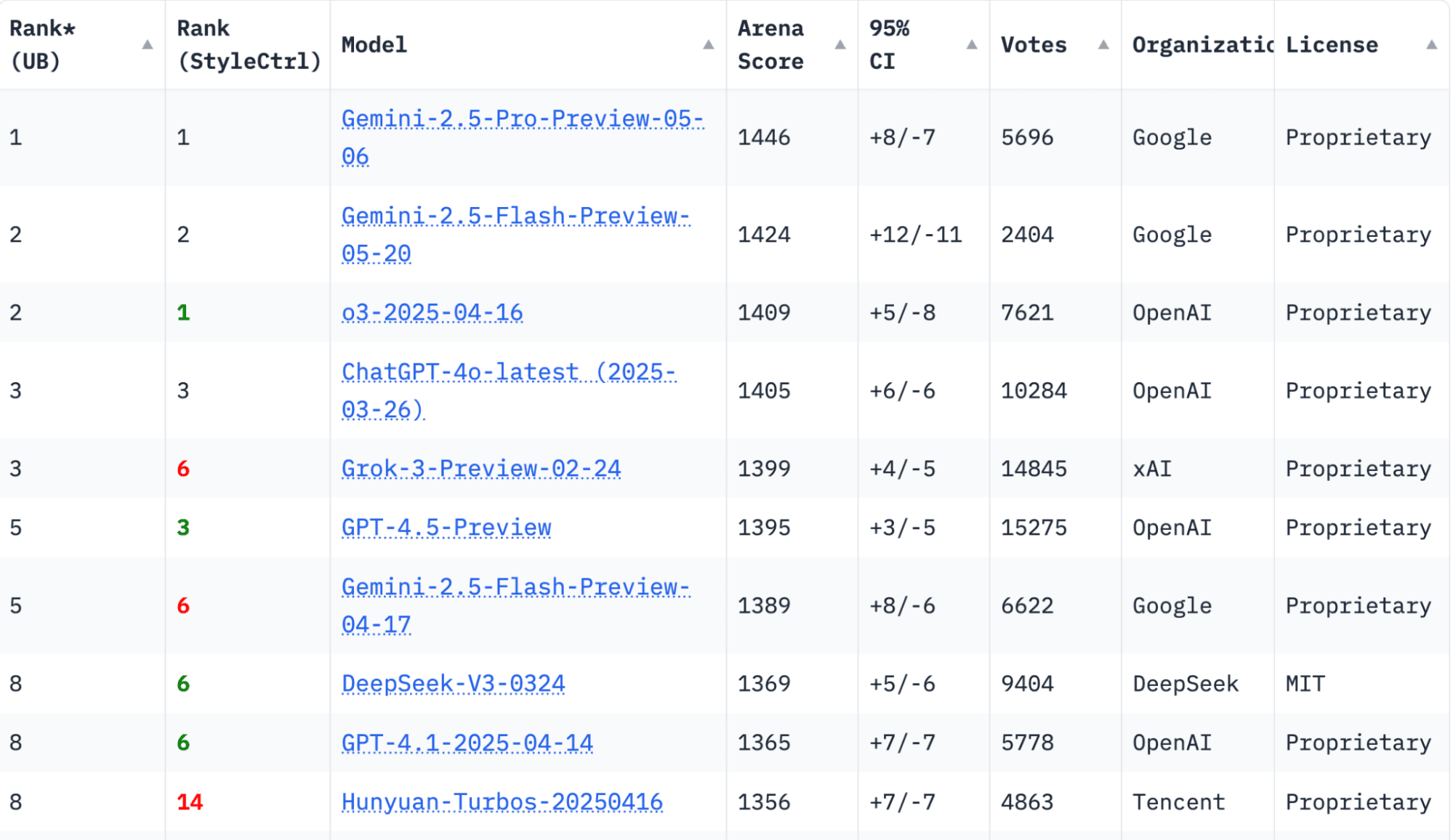
LM Arena (May, 20th 2025)
Start with platforms like LM Arena, where you test two models side by side and vote for the better one without knowing which is which until after. Millions of votes power a live leaderboard that reflects how models perform in actual conversations.
Other tools like BenchLLM, Rival, and AutoArena dig deeper into metrics like speed, cost, and accuracy.
Problem with Community Leaderboards
Some model providers are actively gaming these rankings.
They’ve been caught hiring workers to vote for their own models in LM Arena battles. Others fine-tune their outputs to sound great in short demos without actually performing well in longer, more complex workflows.
Strategy #2: Run a Vibe Test

That’s where the vibe check comes in. Benchmarks don’t tell you:
Is the model helpful and enjoyable to use?
Does it match your brand voice?
Does it explain too much? Too little?
Is it funny? Cold? Too formal?
The VibeCheck System help surface these qualitative traits with systematic testing. But even without tools, you can spot the differences fast:
GPT-4o feels emotional and expressive. Claude feels safe and thoughtful. Llama feels light, fast, and playful.
Strategy #3: Think Practically
Beyond quality and tone, ask yourself:
What’s the latency and cost? Use tools like LLM Pricing to understand real usage costs.
Where can it run? Need offline or private access? Use open-source models like Llama or Qwen. Want hosted simplicity? Go with cloud-only APIs like Claude or GPT.
Does it integrate easily? Some models are just easier to wire into your stack. Test that early.
Or Let Wordware Handle It
You don’t need to track every model update yourself. Wordware helps you evaluate models automatically based on your specific needs.
Want something expressive and concise? Or something serious and technically accurate?
Just tell Wordware what matters, and it handles the testing for you. It keeps track of model shifts over time, so you always use the best tool without redoing the work every month.